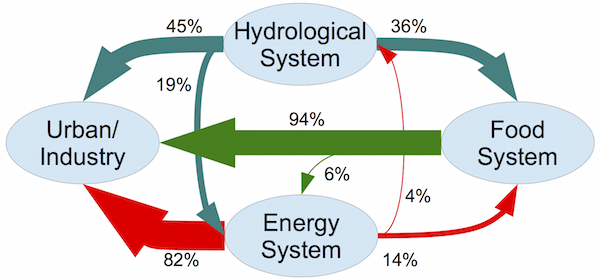
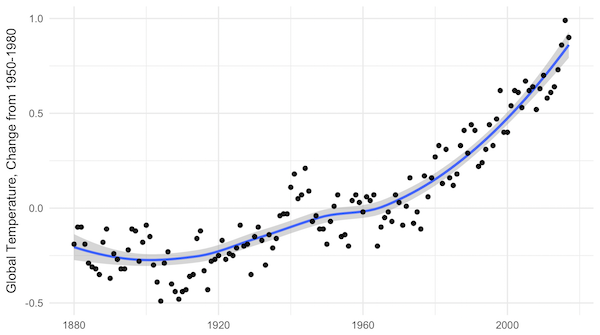
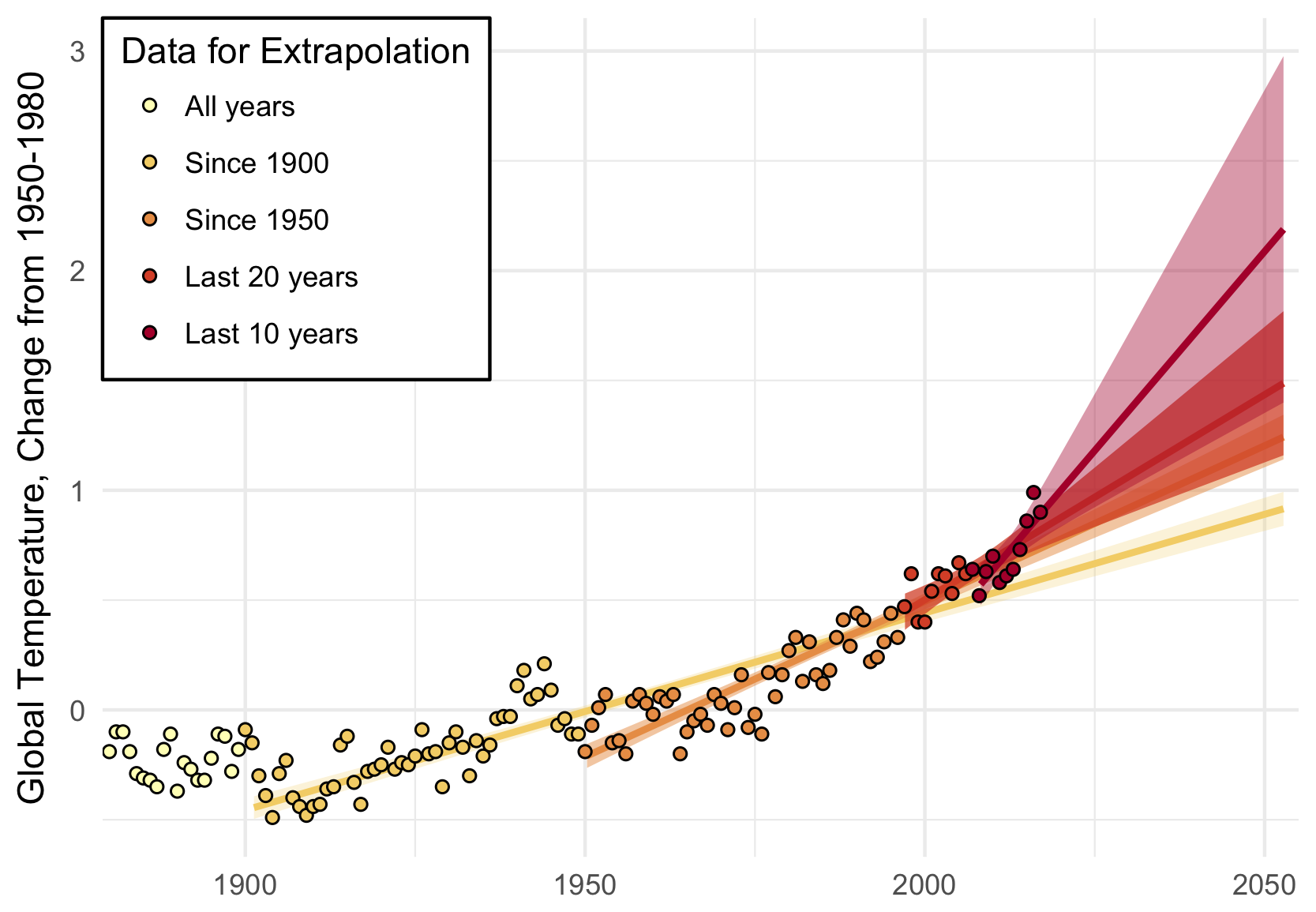
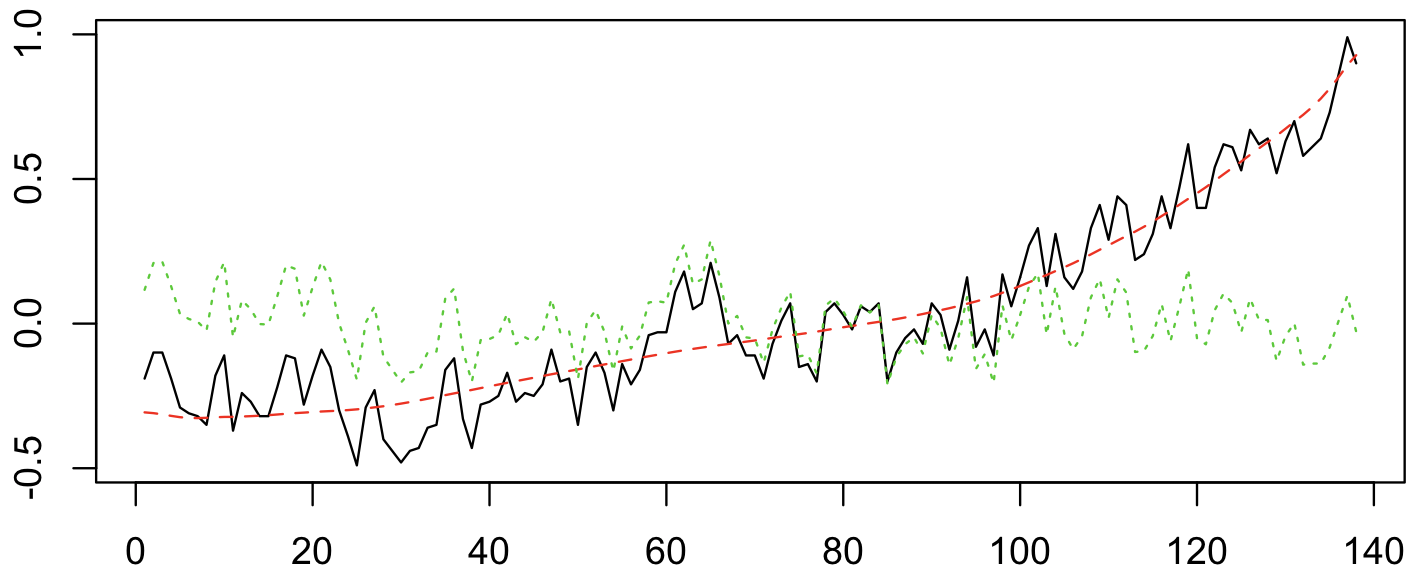
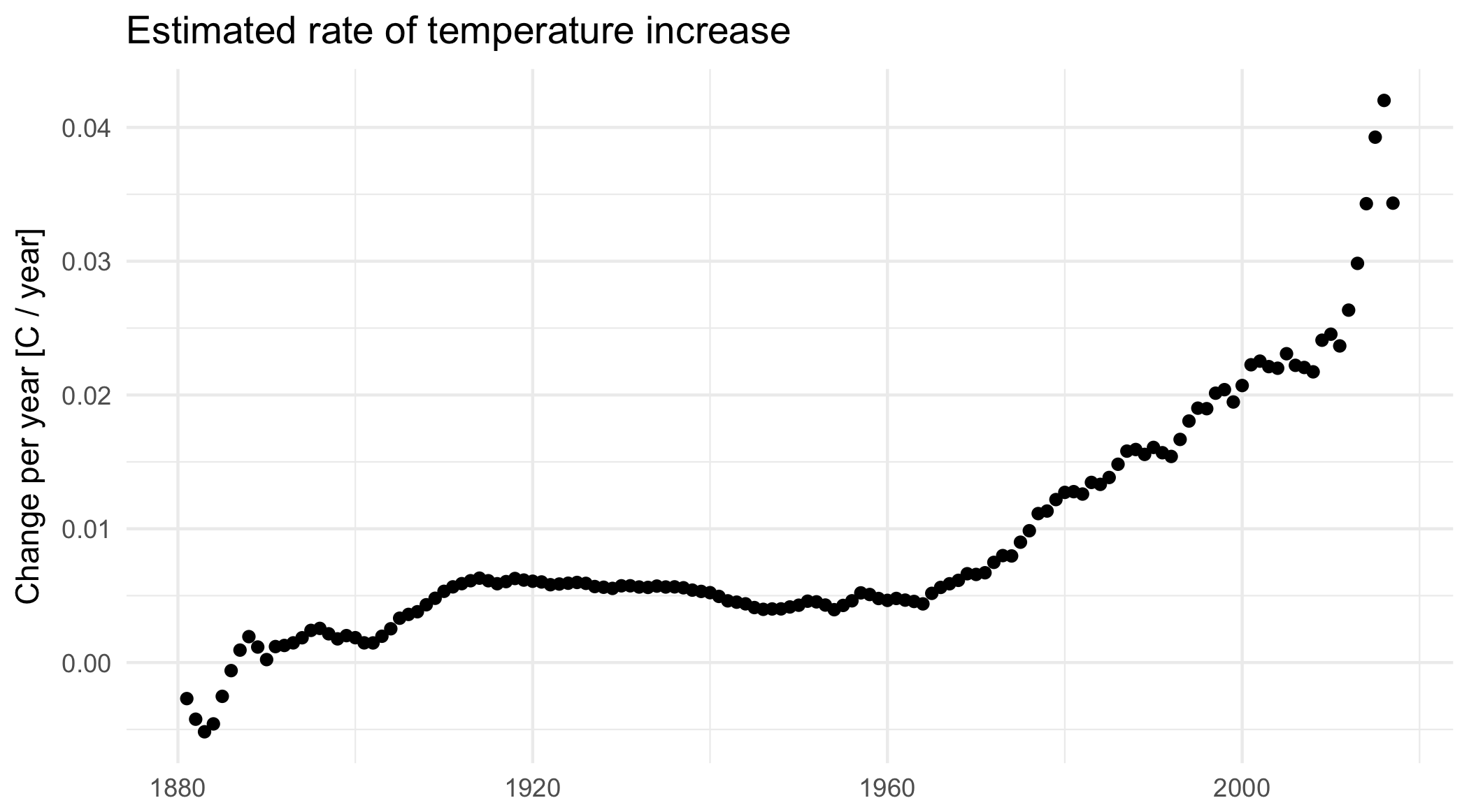
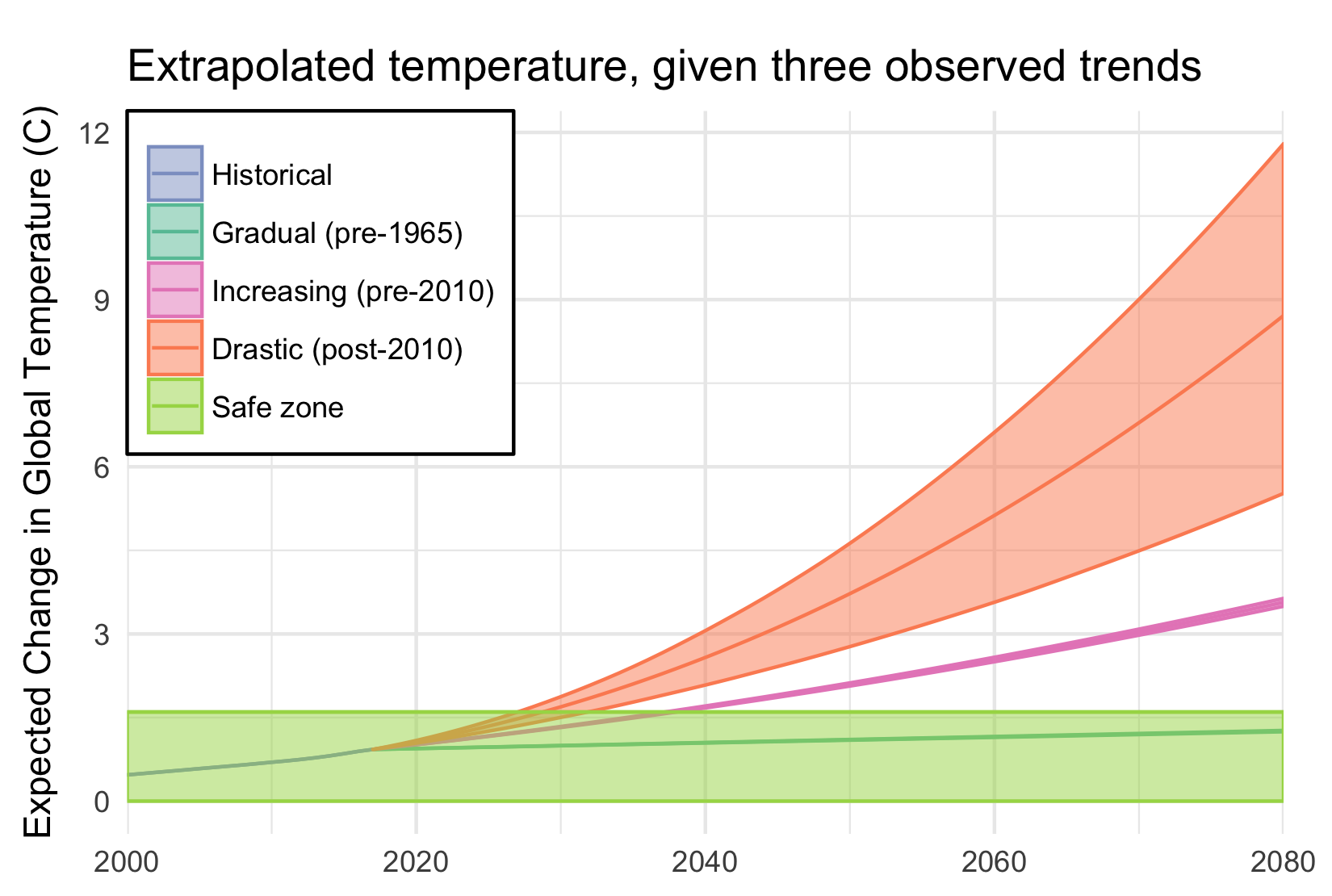
When I tell people I study climate change, sooner or later they usually ask me a simple question: “Is it too late?” That is, are we doomed, by our climate inaction? Or, less commonly, they ask, “But what do we really know?”
With our new paper, Estimating Economic Damage from Climate Change in the United States, I finally have an answer to both of these questions; one that is robust and nuanced and shines light on what we know and still need to understand.
The climate change that we have already committed is going to cost us trillions of dollars: at least 1% of GDP every year until we take it back out of the atmosphere. That is equivalent to three times Trump’s proposed cuts across all of the federal programs he cuts.
If we do not act quickly, that number will rise to 3 – 10% by the end of the century. That includes the cost of deaths from climate change, lost labor productivity, increased energy demands, costal property damage. The list of sectors it does not include– because the science still needs to be done– is much greater: migration, water availability, ecosystems, and the continued potential for catastrophic climate tipping points.
But many of you will be insulated from these effects, by having the financial resources to adapt or move, or just by living in cooler areas of the United States which will be impacted less. The worst impacts will fall on the poor, who in the Untied States are more likely to live in hotter regions in the South and are less able to respond.
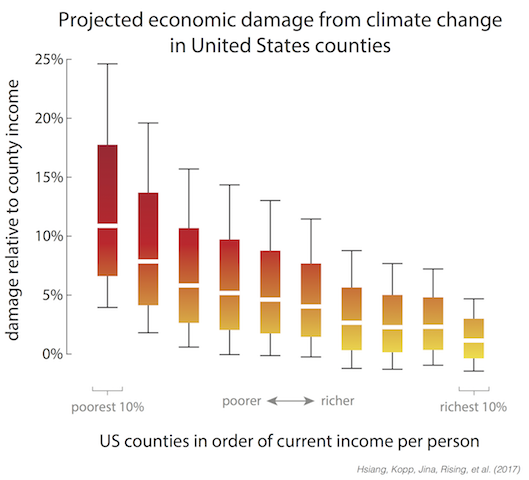
One of the most striking results from our paper is the extreme impact that climate change will have on inequality in the United States. The poorest 10% of the US live in areas that lose 7 – 17% of their income, on average by the end of the century, while the richest 10% live where in areas that will lose only 0 – 4%. Climate change is like a subsidy being paid by the poor to the rich.
That is not to say that more northern states will not feel the impacts of climate change. By the end of the century, all by 9 states will have summers that are more hot and humid than Louisiana. It just so happens that milder winters will save more lives in many states in the far north than heat waves will kill. If you want to dig in deeper, our data is all available, in a variety of forms, on the open-data portal Zenodo. I would particularly point people to the summary tables by state.

What excites me is what we can do with these results. First, with this paper we have produced the first empirically grounded damage functions that are driven by causation rather than correlation. Damage functions are the heart of an “Integrated Assessment Model”, the models that are used by the EPA to make cost-and-benefit decisions around climate change. No longer do these models need to use out-dated numbers to inform our decisions, and our numbers are 2-100 times as large as they are currently using.
Second, this is just the beginning of a new collaboration between scientists and policy-makers, as the scientific community continues to improve these estimates. We have built a system, the Distributed Meta-Analysis System, that can assimilate new results as they come out, and with each new result provide a clearer and more complete picture of our future costs.
Finally, there is a lot that we as a society can do to respond to these projected damages. Our analysis suggests that an ounce of protection is better than a pound of treatment: it is far more effective (and cheaper) to pay now to reduce emissions than to try to help people adapt. But we now know who will need that help in the United States: the poor communities, particularly in the South and Southeast.
We also know what needs to be done, because the biggest brunt of these impacts by far comes from pre-mature deaths. By the end of the century, there are likely to be about as many deaths from climate change as there are currently car crashes (about 9 deaths per 100,000 people per year). That can be stemmed by more air-conditioning, more real-time information and awareness, and ways to cool down the temperature like green spaces and white roofs.
Our results cover the United States, but some of the harshest impacts will fall on poorer countries. At the same time, we hope the economies of those countries will continue to grow and evolve, and the challenges of estimating their impacts need to take this into account. That is exactly what we are now doing, as a community of researchers at UC Berkeley, the University of Chicago, and Rutgers University called the Climate Impacts Lab. Look for more exciting news as our science evolves.